首先,我們要有一些描述電影的特徵,可以包括:
以上都是可以用來描述電影的特徵值,讓我們能夠用 KNN 來找出哪些電影的特徵很像,從而進行分類。
KNN 演算法的原理就是:找到最接近的幾個鄰居,然後看看它們的分類是什麼。
比如說現在有一部新電影要分類,那就需要找到幾部跟它特徵最接近的電影,然後根據它們的類別,來決定這部新電影的類別。如此 KNN 可以根據使用者喜歡的電影,幫忙找到類似的電影來推薦。
大致步驟如下:
(1)計算新電影和其他電影的距離。
(2)找出最近的幾個電影。
(3)讓新電影的類別和這些最近鄰居的類別一致。
比如說,如果你喜歡的是 90 分鐘長的愛情片,KNN 就會去找跟這部電影特徵「很接近」的其他電影,像是找到 90 分鐘長的浪漫喜劇,這就是鄰居的概念。
接下來實作一個 KNN 演算法題目,用之前學過的 Numpy 和 Pandas 技術。這次我們會用歐幾里得距離來計算兩部電影之間的距離,然後再進行分類。


歐幾里得距離函數:euclidean_distance 函數用來計算兩部電影的距離。它的作用是衡量兩部電影之間有多「接近」,公式如下: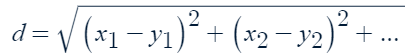
np.sqrt:是 NumPy 中用來計算平方根的函數。
KNN 演算法:knn 函數是核心的 KNN 算法,它會找出最接近新電影的 k 部電影,然後根據這些鄰居是否推薦來決定新電影的推薦結果。這裡是整個題目中最難的地方,很複雜~~大致的步驟如下:
(1)計算距離:計算新電影與資料集中每部電影之間的距離。
(2)排序鄰居:根據計算出的距離,找出最近的 k 個鄰居。
(3)投票決定推薦結果:根據這些鄰居的推薦情況,決定新電影是否推薦。
[26行]:將每一部電影的特徵取出來,並且把它們轉換成一個 NumPy 陣列。根據索引 i 來存取第 i 行的資料。對應的欄位是 length、genre、rating。用這些數值來計算距離,最後這些數值會被放進一個 NumPy 陣列 movie 裡。
[27行]:用來計算新電影和資料集中第 i 部電影之間的歐幾里得距離。euclidean_distance 函數接收兩個參數,一個是新電影的特徵 new_movie,另一個是目前迴圈的電影特徵 movie,然後根據歐幾里得距離公式來計算它們之間的距離。
[28行]:
將計算出來的距離 dist 和對應電影的推薦標籤 df.iloc[i]['recommend'] 放到 distances 清單裡。df.iloc[i]['recommend'] 會根據索引 i 取得電影的推薦標籤,這個值不是 1(推薦),就是 0(不推薦)。
[31行]:
使用 sort 函數,根據每個 distance(距離)對列表進行升序排序,這樣距離最小的電影會排在最前面。key=lambda x: x[0] 表示我們只注意每個元素的第一個值,也就是距離。
[32行]:
提取出最近的 k 個鄰居,這裡的 [:k] 代表取出排序後列表的前 k 個元素(最近的 k 部電影)。
[35行]:
使用列表生成式來提取出每個鄰居的推薦標籤 neighbor[1],也就是 1(推薦)或 0(不推薦)。sum([neighbor[1] for neighbor in neighbors]) 會對這些推薦標籤求和,也就是計算有多少鄰居推薦這部新電影。
[38行]:
進行條件判斷,如果推薦的電影數量超過鄰居數量的一半,就返回 1,即推薦這部新電影。如果推薦數不超過一半,則返回 0,表示不推薦新電影。



學完這個 KNN 小專題後,我覺得這是一個很好的AI入門知識,讓我可以用簡單的方式理解一個核心的機器學習概念。事實上, KNN 就是看「新資料點」跟哪些「舊資料點」比較相似,然後依據這些鄰居來決定結果。
像這次的電影推薦系統,其實就是根據電影的「時長」、「類型」、「評分」來看哪些電影比較相似,然後看那些相似的電影有沒有被推薦過。如果大多數推薦的話,新的電影也會被推薦。這樣一來,透過相對簡單的數學運算,我們就可以做出有智慧的判斷,真的蠻酷的><

